re:Invent 2020 - Final Keynote with Werner Vogels

Today marks the beginning of an end for the re:Invent 2020. Sure, there are still some sessions lined up, and additional content is coming up in January. Even, the final keynote of Werner Vogels has traditionally marked that we are near the finish line. And I don’t think this year it is any different. People start to go back to their normal routines gradually - and under normal conditions would begin the long way back home from dusty plains of Nevada.
DeepRacer
But before diving into the details of today’s main event, let’s discuss a bit about how DeepRacer leagues have been progressing - and now it is time for finals. This year, the finals is an interesting faceoff between 8 finalists driving simultaneously on the same virtual track. And the track is nowhere near as simple as what it used to be during last year when everyone was still learning.
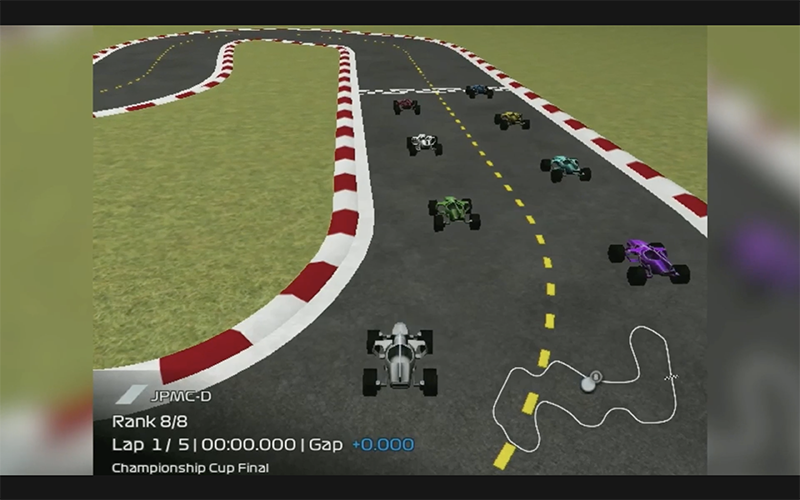
To be fair, the conditions in the virtual track are always optimal from lighting, track surface and other environmental conditions point of view as well as there is no difference in car suspensions, performance or battery levels and so on. But that is very much compensated by far more complex setup of track profile and multiple moving obstacles (that is, the opponents) on the track.
There is also last-minute drama, as the leading car misbehaves at the final stretch and when drama concludes, we have a new champion. Congrats to Po Chun!
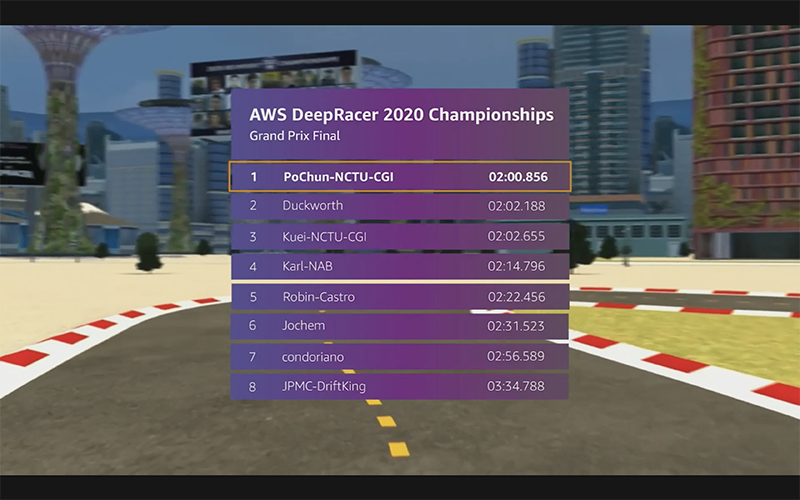
This segment was pre-recorded, but we could still certainly feel the excitement of the race regardless.

So, the trophy has a new owner - let’s see what is in store for next year and how much more advanced can the challenges get before you need some next feature introduced to the cars.
Werner on a bike
As all travel in many companies - including AWS - is more or less limited or completely halted this year we learn that Werner will not be joining us from the US, but actually from his native Netherlands and Amsterdam. We can see him - or we can only assume it is him - bicycling through the busy streets of Amsterdam. And if you have not ever experienced the dutch bicycle culture, it can get crazy, I can tell you that much.

Werner joins us from the old sugar factory as a backdrop to lead his keynote and leadership session through the virtual forum. This session is entirely pre-recorded but breaks out from the familiar “on stage” format to more close and personal take on a keynote. We won’t be seeing too much of slides or diagrams this time, so mostly just speaking and few emphases here and there, but all in all the format is refreshingly different and somehow “organic”.
It will quickly come apparent that we will learn a lot today also about sugar factories, not just IT. Let’s see what there is to learn from the 150-year-old factory for modern times. (Spoiler alert: a lot).
The global transition
The global business landscape has been shaken globally like it has not seen in many decades. Sure, there has been a financial crisis, but they have not been so profound in ways that affect the lives of every person on the globe. Virtually every business and individual has needed to adapt their behaviour and actions to survive. And when there is a major disruption, there are the ones who can adapt and succeed and unfortunately also the ones who can’t.
Working at IT, we all have immense possibilities to impact the success of the clients and the businesses we work with. Many things had made the transition from physical to digital, and there is a high demand for people creating and operating these systems at scale.
According to Dr Vogels, same applies to AWS: AWS has been supporting the remote way of working for a long time and tools and processes were in place for teams located all over the world. And let’s be fair - even those companies traditionally quite reluctant to support remote work have had to come to terms of the realities.

Additionally, it just so happens, that AWS disaster response team was founded some years ago, which was meant to be able to respond to environmental incidents. Still, it could, in this case, be used for responding to the aftermath of a global pandemic.
Today we are showcased with some customer cases, how their business had been transformed and how they were able to react to the pandemic situation. Additionally, the very nature of cloud services has been hugely successful in being able to scale up on demand very rapidly, when new business models have been created from the ground up. We hear cases from companies like Ava processing over 300TB of health data in S3; and Zoom experiencing 30x growth and deploying 5000+ servers daily in the peak of the pandemic when everyone suddenly started working and studying from home; and Lego and how they have made the transition to serverless to support the ever-growing demand flexibly.
And when considering the global issues affecting everyone, the environmental and sustainability message is something that is vocalized heavily. I don’t think there has been a single keynote this year, which has not underlined the awesomeness of Graviton2, whether it is price, performance or energy efficiency. AWS probably also has own agenda in pushing something they can produce independently from Intel, but you can’t argue that being cheaper, more performant and using less energy are bad selling points. And most of the regular Linux based workload should work just fine on it.
As a side quest, we are dropped with AWS CloudShell, which is basically AWS CLI you can now use directly from AWS dashboard and is integrated with the IAM credentials you are logged in straight from the box. You can find the shell icon in the top bar of your dashboard view in the supported regions, and after a quick test, it just seems to work as promised.
Step up from fault tolerance
The ultimate goal for running a stable and predictable system in one term could be quantified as dependability. That should be considered as the next level from just bare fault tolerance, which is not a bad goal in itself. But dependability can be said to compose of different aspects of implementation and operations, like availability, reliability, safety and observability, to name a few. In case of faults, it is also a lot about fault prevention, fault removal, as well as fault observability. And in case of changes to the system, it is about foreseen changes, foreseeable changes and unforeseen changes.
Dependability can be achieved through several means on these different topics. One example is implementation diversity: to drive the dependability, there can be two components doing the same thing built separately for the same purpose. Those could be two UPS controllers in data center infrastructure or two generators in a factory. These principles are still applicable today, which were used in building factories and plants in the past.
But as with many things, dependability needs to be also a balancing act between complexity, risk and investment.
As an example from dependability, let’s take one of the most widely used services in AWS: S3. The majority of S3 access patterns is now machine to machine, and peculiarly enough, machines have a lot harder time to handle eventual consistency. That has been a traditional design element in how S3 has operated for modifying existing objects: with eventual read after write consistency. As there was a clear requirement form the standpoint of increased dependability, S3 functionality has been amended to include strong read after write consistency. So, this specific circumstance does not need additional exception handling at the client-side and greatly simplifies some implementations of client software.
As a base problem, the eventual consistency was more or less of a mathematical and statistical problem: how probable it is that you would hit a read that was not consistent? Figuring the consistency of a system is something, where a mechanism called algorithmic reasoning can assist. More complex the environment is, the more essential tools like this will be. These tools conducting algorithmic reasoning use a method called formal verification which is a method based on mathematics to assess the completeness of implementation.
One example of such tool announced earlier during the event is Amazon VPC reachability analyzer, which can without sending a single packet to be used to analyze, for example, access from one server to another. That is based purely on mathematical analysis, not on actual network testing.
Why AWS builds things as they do
Sometimes there needs to be made tradeoffs between what is familiar and safe and what is new and risky. For specific purposes, it makes sense to use an implementation that has clear advantages for the use case, even if that would sometimes mean to go and learn new tools and technologies.
“Operations are forever” so you also need to consider, what would be better for the long-term success of the system, not just what is in your toolbag today. You are going to carry the selections you make today for years to come. One example is that Rust. has become increasingly important at AWS as an implementation language to build performant and reliable services.
Making sure that the system usability is on a high level, AWS is as part of their culture answering to the hypothesis, what if you have faults in your input data. How do you know that system continues to be dependable regardless of input?
Chaos engineering is a concept which was popularized originally by Netflix. And the original implementation was Chaos Monkey (which is actually just one type of Monkey they used), which was randomly terminating instances. The architecture was supposed to withstand any single instance failure without impact for the production. After the initial days of Chaos Engineering, the method has evolved quite a lot to being accepted as a household approach for ensuring the usability of modern serverless architectures. You should take a look at Adrian Hornsby’s article series. Read the Adrian’s article series.
Do you know how your application responds to issues injecting failures to your systems? That has required principles, commitment and tooling to adopt the ways of chaos engineering - not to speak about understanding, that what is the correct amount of chaos to validate the hypothesis and not impact the production. After all, the whole purpose is to make sure that the infrastructure can withstand chaos, not overwhelm it by chaos.
Simplifying chaos experiments is something I know a lot of my peers, especially focusing on the serverless, are valuing greatly. AWS announced today AWS Fault Injection simulator which is coming “early 2021”. It is going to be a “trained chaos monkey in a box”. And on that note, I think it is safe to conclude, that Chaos Engineering is accepted as mainstream if there was still some doubt.

As Werner himself puts it: “there is no better way to test your systems that chaos engineering” and continues to make a bold statement that this is the announcement during the whole event he is “most excited about”.
Systems control theory
Interestingly enough, I just recently held one talk about what there is to learn about industrial systems and take to IT and made some exact points about systems control theory and control engineering. The traditional theory discusses mostly about single input - single output systems. Still, the principles can be taken to multiple inputs - multiple output realms as well. Still, the cascading effects can become quickly quite complex, so I can understand why the presented theory was kept mostly on the traditional aspects. And to be fair, it serves the use case here quite enough.
The theory has been used to build a lot of dependable industrial systems dating back well over a hundred years. We will need to understand if the system is controllable and observable (or unobservable). If we focus a bit on the latter from the point of sensing failure, classical monitoring deals with two questions: what is broken and why it is broken. And the basic paradigm in the classical sense of control theory is that you can’t predict breakdown, only take action when they do.
Additionally, in factories, it was unlikely that the operator of a factory or station could repair the system, even if they would have a dashboard containing each important metric in front of them. The traditional way was to put every important metric to a dashboard which the operator was looking at.
In modern, complex systems, it is impossible to put everything on a single dashboard and it to make sense. And this starts to lead us to the conclusion that monitoring is not the same as observability.

So the question now is, how can we make sure we have data, tools and mechanism to resolve problems quickly?
Towards full observability
We often talk about monitoring and alerting as basic concepts. Still, the systemic approach to fully understanding what is going on at a certain point in time with a workload can be described as Observability. Observability has three key mechanisms where it is built on: metrics, logging and tracing. And to make things more complicated, these all can exist in component, system and service level to some extent.
As Werner concluded in last year’s re:Invent “log everything”, as the logs are the source of truth. But the other harsh truth is that large amounts of logs and large cardinalities of metric make it expensive and virtually impossible for humans to understand even the single data streams, not to speak of cross-referencing them.
Lots of individual components contribute to the processing of a single request and tracing such request end to end can be extremely difficult, if there are no additional mechanisms to help in correlating that data. The standard approach for this is to inject a trace ID to the request, which can be then traced through the invocation chain.
But as Becky Wise from AWS puts it, automation is necessary, but not enough for operational excellence. From the metrics point of view, it is not as simple as stating that a certain type of metric always means a certain outcome. Examples of such scenarios could be for example “more is better” vs “more is worse” and additionally when there is no output “no news is good news” vs “no news is bad news”. The basic dilemma of push-based monitoring / alerting has always been, that everything is silent, how come you know everything is OK, or if everything is extremely broken.
To support the goals of observability, few open source tools that have come very popular in operations, where one is Prometheus, and one is Grafana. And today we are glad to hear that there is a new service in preview for both, under the names of Amazon Managed Service for Grafana and Amazon Managed Service for Prometheus. For once, the naming is clear and concise.
Additionally, there is the small, last announcement of the day for AWS distro for open telemetry.
Conclusion
When you have slow, difficult or time-consuming tasks to manage, taking advanced technologies to simplify them is something to be considered. Today we have taken a closer look for a few of these concepts that could be found useful in everyday implementations you might also have.
If you are a builder, the key takeaway from today is that stay one step ahead. Keep learning and acquire new skills in your toolset. The world is changing, and you need to keep up. As an example, now it is the time to start thinking of quantum computing, and it’s possible relevance for solving the programming challenges of the future.
And on that note, as Werner conclude as well, Go Build!