re:Invent 2020, Machine Learning Keynote - level keeps on rising

Machine Learning (ML) keynote is the third keynote of the re:Invent 2020, and today we join with Dr. Swami Sivasubramanian, VP of Amazon Machine Learning to hear the latest news and industry trends & visions on Machine Learning and Artificial Intelligence. Machine Learning is, and continues to be, one of the most disruptive technologies we will encounter this decade. It is only fitting, that it has secured it’s own keynote in the roster for this year.
Amazon has been an early adopter of ML in the core of their business and most of the portfolio and announced services are the ones, that they have developed for their use and have done productisation work to offer them also for others to consume as well. As ML gets more and more widely adopted as the de facto mode of operation to understand your operations and data and your customer behaviors, we are presented few major business cases, where ML has been used to enhance, transform or even disrupt business. Customer examples from companies like Domino’s, Roche External, Kabbage, BMW, Nike and F1 for use cases like prediction, forecasting, analytics and forensics, just to name a few.

The AWS Machine Learning and Artificial Intelligence story started with three launches in re:Invent 2016, which were Lex, Polly & Rekognition. This year, there is 250+ features available in the ML & AI portfolio ranging from generic ML infrastructure components to high abstraction, business-centric and ML enabled PaaS and even SaaS services.
Freedom to invent
Innovation requires experimentation, but it also requires failure. And freedom to invent is all about enabling people with proper tools. Naturally, in different roles, the appropriate tools might be different, depending on if you are a developer, manager or data scientist.
Different roles need different enablement, and different types of ML services are useful for people in different roles. There is more clearly defined distinction in the ML services to three different categories:
- Machine Learning Infrastructure & Algorithms
- Machine Learning Platform
- Business Services
There is an inverse relationship between how much knowledge & training each realm requires and how much there are currently, or arguably even potentially, people available to work in each segment.
That can be more or less trivially visualised as follows:

Justifications and reasons why Business Services segment is the one where we see more and more gravitas is many-faceted. Few points to make therefrom the diagram above naturally is that the pool size is quite limited for people who are able to work on the infrastructure and algorithmic level. Even with proper training and education, it takes time to build talent. On the other hand, the Business Services are directly consumable by any developer or data scientist without the need for detailed information on the inner workings of the algorithms - though it can be beneficial for sure in real-world applications. Also, it makes a lot of sense to start somewhere and reap the low hanging fruits of ML enabled services. Additionally, and this is probably a business benefit only for the service provider, there is a stronger commitment to using a service which is specific in its API. So if you have committed to AWS solution, there is a strong possibility, that you are in it for the long haul.
But let’s move back to the context of the keynote.
Five different principles similar to Andy Jassy’s keynote are presented to use, this time referred to as “Tenets”. Swami’s tenets, which act as the structure for today’s keynote are:
- Provide firm foundations
- Create the shortest path to success
- Expand Machine Learning to more builders
- Solve real business problems, end to end
- Learn continuously
Some of these are for sure the same ones from Andy’s list, with maybe a bit different focus.
We will take more detailed look at each of these, and how these relate and match to the three categories and abstractions we defined for Machine Learning services.
Provide firm foundations
The applications of ML are many, but some of the challenges are mutual. The hardware and software building blocks of ML applications are continuously developing and keeping the infrastructure healthy is a burdensome job. AWS aims to provide a highly integrated and optimised ML infrastructure on top of which the successful Machine Learning and data analysis workflows can be built.
What lies in the future for Machine Learning applications? We are seeing first iterations of self-driving cars, eventually full autonomous driving, autonomous systems understanding natural language communication. That is more and more real every day, but it still remains the fact that Machine Learning is dependent on the data, and it’s quality as well as requires intense resources for complex applications. For example, training a complex deep learning model can take anywhere from hours to weeks to conclude.
AWS is positioning themselves very strongly in all of the three categories we mentioned earlier. Starting from the infrastructure and algorithm layer with support of multiple purposes built instance types and machine learning AMIs. It tells something about AWS prevalence in the Machine Learning scene that according to Swami, over 90% of cloud-based workloads of popular ML frameworks TensorFlow and PyTorch are on AWS.
What adds to the complexity of problem-solving is that every machine learning project is different from its specific requirements for infrastructure. The requirements vary not only based on the chosen framework for solving the problem but also about the amount, type and quality of data. There needs to be some balance, for sure - circling back to one of Andy Jassy’s themes of “Don’t Complexify” - framing the solution with a limited set of known tools might be still more productive than to think that every problem is a snowflake.
One specific challenge currently in Machine Learning at scale and in complex cases is the need for distributed training, which requires expertise and experimentation. There are two paradigms involved, which are data parallellism, meaning splitting data across multiple processors and model parallellism, which splits the trained model itself across multiple processors. The new announcement of Faster Distributed Training on Amazon Sagemaker is an interesting addition meant for resolving the problem and promises to complete distributed training up to 40% faster. Real-world results most likely vary based on your problem framing.
Create the shortest path to success
Not quite a long time ago, Machine Learning development was a complicated and costly process. Mostly this was due to the fact, that even though the separate steps were not necessarily that complicated as individual tasks to execute, there was a lot of manual work and it required understanding how to orchestrate the ML development workflow. One very fundamental service from AWS portfolio set to resolve this problem was Amazon SageMaker - which can, to some extent, be described as a Machine Learning IDE.

Currently, there are tens of thousands of customers using SageMaker, including Amazon itself.
Keynote dives to one specific and interesting use case, where NFL has used Next Gen statistics based on Machine Learning powered by SageMaker from 2017. One specific use case with them has been analysing cases which had led to athlete injury.

Helmet analysis and optimisation have led to 99.6% of athletes to use the best performing helmets, which led to 24% drop in concussion rate from season 2016 onwards and the change has sustained on that achieved level. One question that can be asked, which is actually relevant in many cases when dealing with optimisation problems that are you optimising around the correct parameter. Probably in the case of American Football, changing some fundamental part of the sport rather than optimising on better helmet performance might be something that is not a choice that could be easily suggested.
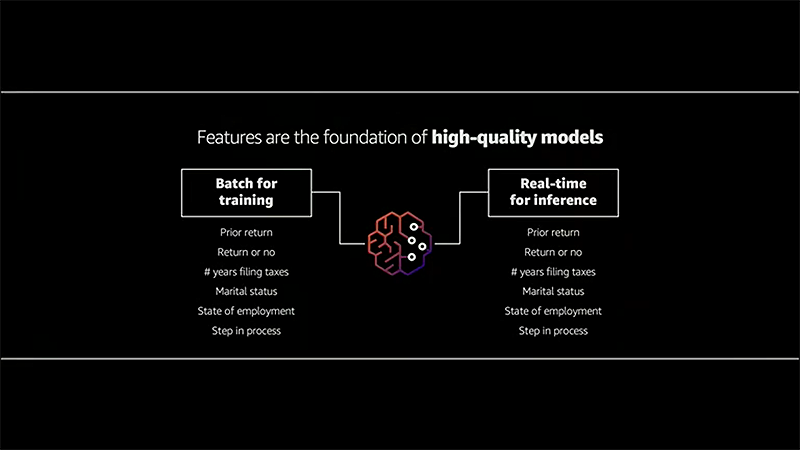
One cornerstone of any good ML result is data. AWS Data Wrangler, which was first announced last week, is a service for aggregating and preparing data for ML purposes. In addition to using AWS native data sources, Data Wrangler will provide some very useful plugins in the near future to import data from, for example, Snowflake or MongoDB. But it is very important to understand that the results still are only as good as your data is, so regardless of the platforms that can be integrated through Data Wrangler and how easy that would be, the quality needs to be there first. Otherwise, the results will not be good and what you expected. When you have curated data, SageMaker Feature Store can be used to store the curated data for secure sharing and future use of ML features.

The other cornerstone to understand is that features are the foundation of high-quality models.
Newly announced Amazon SageMaker Clarify allows for automatic bias detection across the end to end machine learning workflow. Mitigating model bias actively as part of the model development is important, as bias can show up throughout the ML workflow and removing it is difficult.
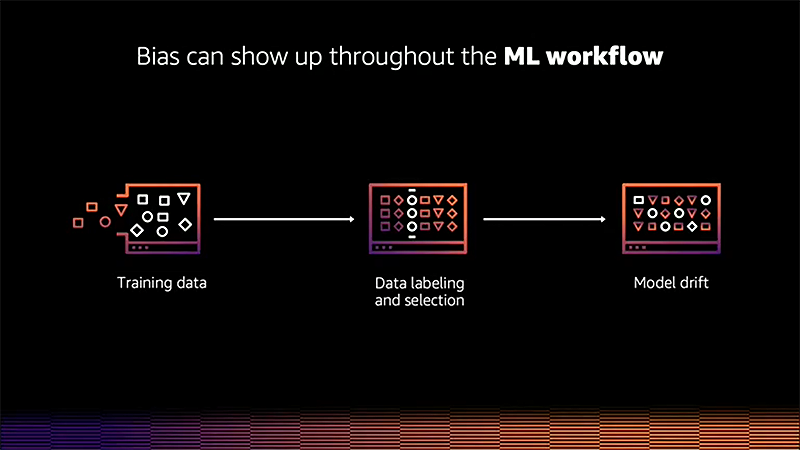
Currently, this is tedious and manual work for data scientists, where Clarify is intended to be of great help.
Thirdly, model training can be a long and costly process, and data scientist want to maximise the use of their resources. But maximising training resources is challenging. To help there is the new announcement of Deep Profiling for SageMaker Debugger, which is generally available today, is a tool meant to help in analysing and visualising utilisation and getting recommendations how to adjust your training workflow.
To “clarify” what these mean in practice, Dr. Matt Wood is at it again with the familiar experimentation on music playlists. This guy clearly loves his playlists - this is something we have come accustomed to seeing past years as something relatable to almost everyone, how data works and what parameters are involved.
DataWrangler and Clarity are both used in the example to make a point, that how to build a model, which is not overly reliant on features, that we know are underrepresented in the data.
Finally, in this segment, the topic of deploying models at the edge. That has traditionally been an optimisation challenge:
- bigger and better models vs limited resources
- more and more devices vs often multiple device platforms
New SageMaker Edge Manager manages and monitors ML models efficiently across fleets of smart devices. It allows integration to edge applications and visibility to the performance of models running at the edge.
As a conclusion, AWS makes the case, that SageMaker is currently the most complete, end to end solution for machine learning development with a single pane of glass. That holds true, at least for today.
Expand machine learning to more builders
This Tenet circles back to our division of different categories of ML services. And how the more higher abstraction level services are the ones, that can be put to hands of more people, who can benefit from using ML in their line of work daily.

There have been some automation tools previously, but traditionally it was required to make a binary choice between manually built models and AutoML created models. The AutoML created models posed a problem that using it provides very little visibility on how the model was created. The modern alternative on AWS platform is the SageMaker Autopilot which creates the first model in minutes from raw data to deploying the model and enables the ML specialist also to fine-tune the model based on the data. Autopilot is also integrating with more data sources natively, like Qlik, Tableau and Snowflake. Snowflake is especially getting much love this year, despite its somewhat competitive positioning against some AWS offerings.

The more significant theme, however, is bridging machine learning to even more builders: for example database developers and data analysts. That requires bringing the tools closer to them, closer to tools these professionals are natively using. Few new interesting tools in this realm are ML tools which are integrated into data stores and BI tools.

Offerings in this category include Amazon Aurora ML, Amazon Athena ML and new announcements of Redshift ML (in preview) and Amazon Neptune ML (GA) which enables predictions on connected datasets utilising Deep Graph Library.
One last example of the high abstraction ML tools is QuickSiqht Q, which was announced last week. It is NLU (Natural Language Understanding) enabled to search for your data, where you can ask the questions in using natural language expressions. You could argue, that this brings ML and data to the use of every manager, regardless of the existing technical competence and without the need for technical assistance to set up complicated dashboards or formal queries against data repositories.
Solve real business problems, end to end
Machine learning solutions are in best use when they are applied to solve real-world business problems. Good candidates for business problems resolvable by ML are the ones which naturally have a business impact, which is rich in data and have not been resolved well with traditional means up to this date.
One example of a very common business problem is searching in the digital domain inside of the enterprise. Most of the current solutions are based on indexing and keywords and do not yield good results in real-world conditions. The results vary from horrible to borderline acceptable, and usually, the user needs to adapt the engine behaviour and not the other way around. Amazon Kendra is a ML-enabled search engine pluggable to a large set of data repositories, and there are now 40+ new connectors available. One of the strengths of this solution has been incremental training, so it also gets better during the time. One downside for sure has been the hefty price tag.

Other examples from AWS current portfolio for direct and existing problems are the Amazon Connect services and Code Guru / DevOps Guru.
On a more generic level of tooling meant to solve business problems, we have such realms like predictive analytics, anomaly detection and ML vision, which can be applied to several different problems in meaningful ways. Dr Matt Wood cites these technologies as “With no machine learning experience required - and that is a big deal” - and this is a trend we addressed in the very beginning.
The tools which were announced earlier for these were Amazon Monitron, Lookout for Equipment, Lookout for Vision and Panorama. The new announcement today was an addition to this lineup with Amazon Lookout for Metrics (in preview), which is an anomaly detection service for metrics with root cause analysis. It has 25 built-in connectors, and performance improves over time.
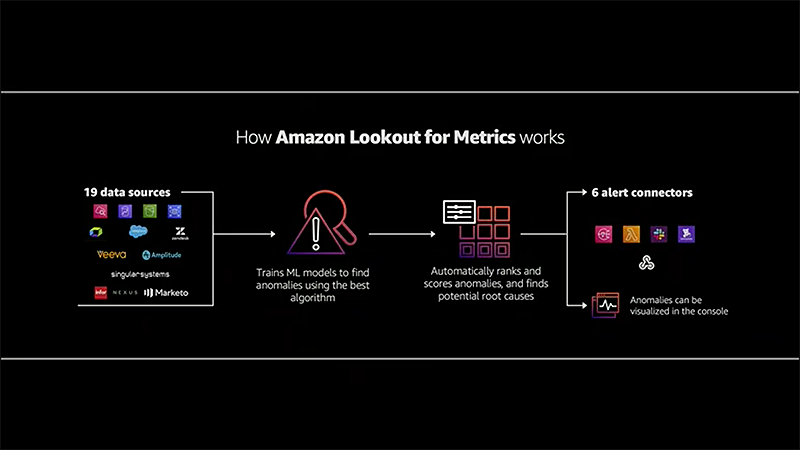
How do these come together, for example, in the manufacturing process? Errors which are detected early can avoid expensive downtime and are directly a cost impacting optimisation. Blind spots are possible points of failure, which can be analysed with sensors, for example for temperature and vibration. Quality in the production line is an important factor (and quality here is not to mean best possible, but always the same output from the process). Misalignments, dents, scratches etc. can be detected by cameras easily, and process can be adjusted.
Additionally, the whole paradigm can be transformed; not monitoring just process, but the environment as a whole, including the premises, logistics and everything that happens in between those.
As Dr Wood puts it, “undifferentiated heavy lifting” is handled by the ML working in the backend to provide the business value and masking the complex implementation in the background.
Additional niche new announcement was made in this segment for Amazon HealthLake, which stores, transforms and analyses health and life sciences data at petabyte scale. It can organise data in chronological order to enable detecting trends and has a built-in query, searches and ML capabilities. Most probably this is initially targeted to US market, but probably we can see some of these landings in Europe eventually as well when the offering gets more mature.
Learn continuously
As one of the Amazon leadership principles states: learn and be curious. That holds a true for Machine Learning more than ever. Everything is still new, and everything is evolving at a rapid pace.

before they were mainstream. A lot of this early legacy can be seen in the portfolio we’ve come to appreciate. But it requires insights and learning to take advantage of all of that.
There is a lot of educational content available, both on and off of AWS platform. You should seek the topics and the style of content that suits you personally and keeps learning.
But one learning platform is special and near to our heart here at Cybercom as well. The AWS DeepRacer still acts as the stepping stone to real-world ML applications and lowers the bar with something easily understandable and well packaged. We have a totally separate story on that subject , which you should check out.

Re:Invent also acts as a learning platform. There are currently fifty ML sessions available through the event, so there is no shortage of interesting content.
Halfway through
We are almost at the halfway point of re:Invent 2020. On Thursday night, we have the Infrastructure keynote, and we will write a weekly recap, which will be out on Friday morning our time.
Stay tuned for an update and have a great week!